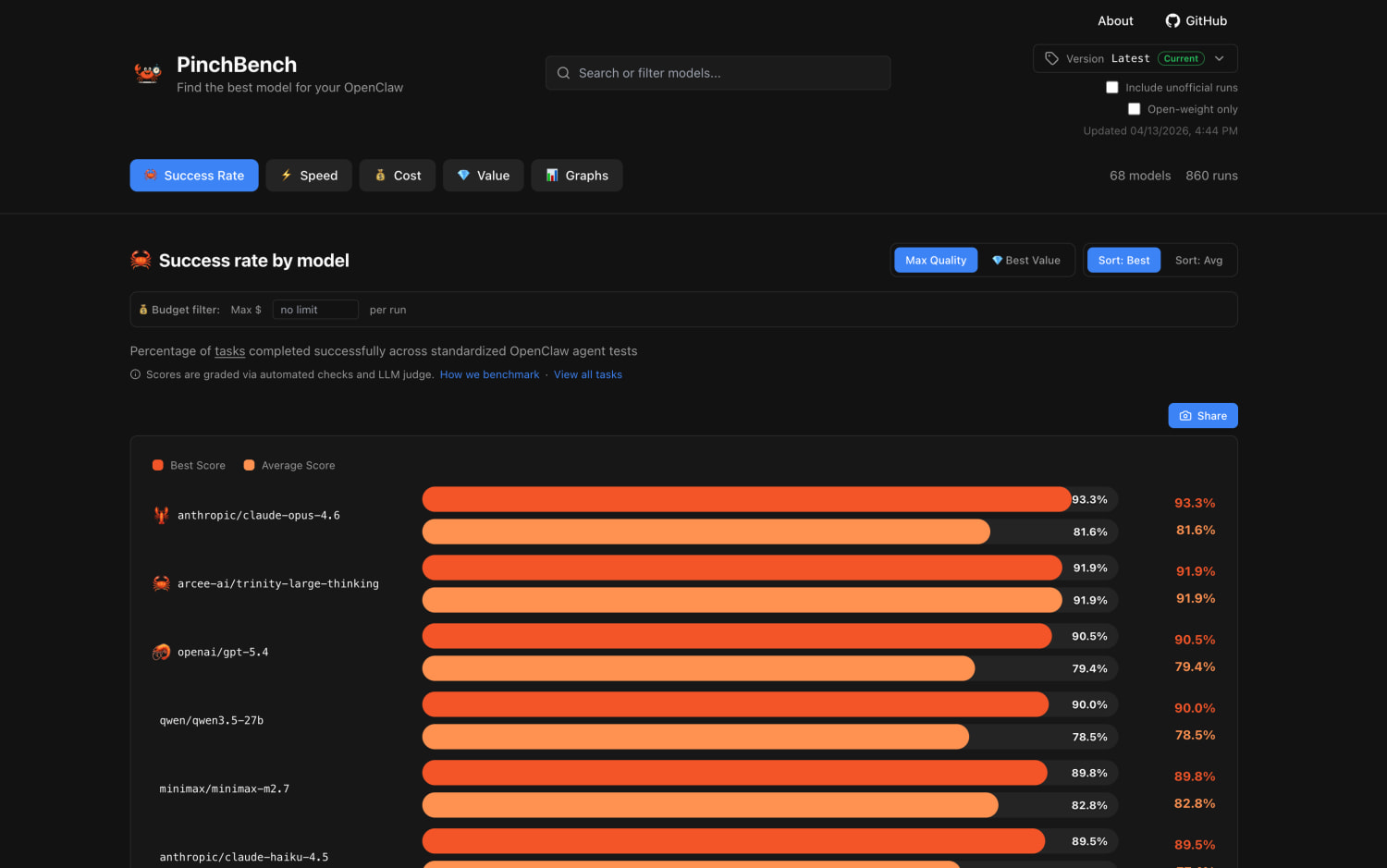
PinchBench是什么?
PinchBench是一个开源免费的基准测试平台,专为评估大语言模型驱动智能体的真实工作表现而设计。它摒弃了传统“刷榜式”评测,通过一系列标准化现实任务,从成功率、速度和成本三大维度量化模型“干活”能力。平台采用自动化脚本与顶尖LLM评委结合的混合评分机制,所有任务逻辑完全透明,帮助开发者精准筛选最适合Agent工作流的最优模型。
PinchBench主要功能
✅️ 真实场景任务评测
摒弃传统的学术考试题,专注于模拟真实世界的Agent工作负载,直接检验模型在复杂、多步骤任务中的实际执行能力和稳定性。
✅️ 混合评分机制
独创性地结合了确定性自动化脚本验证与顶尖大模型作为评委的灵活判断,既保证了评分的客观公正,又能准确捕捉任务完成的质量细节。
✅️ 三维量化排名
从任务成功率、执行速度和消耗成本三个核心维度对模型进行综合打分和排名,为开发者提供一目了然的选型参考,快速锁定性价比之王。
✅️ 完全开源透明
所有任务定义、评分逻辑和测试代码均在GitHub上开源,任何人都可以审查、复现结果或贡献新任务,确保评测的绝对公平与可信。
PinchBench收费策略
PinchBench作为一个开源项目,其基准测试平台和评测数据完全免费向公众开放。开发者可以直接访问官网查看排行榜或克隆代码库进行本地测试,无需支付任何费用。
PinchBench使用场景
模型选型决策:开发者在构建AI Agent产品前,可依据平台排名快速对比不同模型在真实任务下的表现,避免被传统跑分误导,选出最合适的基座模型。
性能回归测试:模型更新迭代频繁,团队可将PinchBench集成到CI/CD流水线中,自动检测新版本模型是否在关键任务上出现性能倒退或行为异常。
学术研究与对比:研究人员可利用其开源的标准化任务集和评分逻辑,作为公平的基线来评估新提出的模型架构或训练方法在Agent能力上的提升。
成本效益分析:对于预算敏感的创业团队,可通过平台的速度与成本维度数据,精确计算完成特定工作负载所需的推理时间和费用,优化资源分配。
PinchBench常见问题
- PinchBench与传统评测榜单有何不同?
传统榜单多测试模型在静态题库上的知识储备,而PinchBench专注于衡量模型驱动智能体执行多步骤、有状态的真实任务的能力,更贴近实际落地场景。 - 如何保证评分的公正性?
我们采用自动化脚本进行确定性验证,同时引入顶尖LLM作为评判者来评估开放性任务的完成质量,双重机制最大限度减少了人为偏见和评分误差。 - 我可以提交自己的模型参与评测吗?
当然可以。平台代码完全开源,你可以按照文档规范在本地运行评测并将结果提交Pull Request,或者联系团队申请将你的模型加入官方排行榜。 - 平台上的数据多久更新一次?
排行榜数据会随着新模型的发布和评测结果的提交进行实时或准实时更新,确保你看到的始终是最新的模型性能对比信息。 - PinchBench主要测试哪些类型的Agent任务?
涵盖网页浏览、代码生成与调试、复杂数据检索、工具调用等多种现实世界中的智能体工作负载,全面考察模型的规划和执行能力。